



コンチェックでんき:電気代のポイントをビットコインにする方法
miho
Hippie Vibes

音声AIの進化は、ここ数年で大きく加速しています。
AIアシスタントとの対話や自動翻訳、音声によるカスタマーサポートなど、私たちの生活やビジネスのさまざまな場面で「声」を活用した技術が広がりつつあります。
こうした音声技術を支えているのが、大量かつ多様な音声データです。とくに多言語・多アクセント・自然な会話に近いデータは、AIの精度向上において重要な役割を担っています。しかし、その供給は必ずしも十分とは言えないのが現状です。
Silencio (サイレンシオ)Voice AIは、この音声データの収集と活用を分散型ネットワークとして設計したDePIN(Decentralized Physical Infrastructure Network)プロジェクトの一つです。
個人が音声データを提供し、その貢献がネットワークの一部として扱われる仕組みを採用しています。
本記事では、Silencioの概要や参加の流れについて整理します。Web3やDePINに馴染みのない方にもわかりやすいよう、基本的な構造から順に解説していきます。
Silencio Voice AIは、DePIN(Decentralized Physical Infrastructure Network)プロジェクトの一つです。
DePINとは、センサーやウェアラブル、音声など、現実世界のデータを人々が分散的に提供することで成り立つネットワークを指します。
Silencio Voice AIは「人の声」を基盤にしたDePINであり、ユーザーは音声データを提供し、その貢献がネットワーク上で記録される仕組みになっています。
Apple WatchやOura RingのようなWeb2デバイスでは、データ管理は主に企業側が担います。
一方Web3では、どのデータを、どの条件で提供するかをユーザー自身がコントロールできる点が特徴です。
従来、LLM(大規模言語モデル)の学習用データは、Web2型データ収集プラットフォームを通じて提供されることが一般的でした。
こうした仕組みでは、データとアカウント情報が同一の管理基盤に置かれるケースも多く、利用者側からはデータの扱われ方が見えにくい場面もあります。
これに対しSilencioは、プライバシーを前提条件として設計されたWeb3プロトコルを採用しています。
Silencioにとってプライバシーは付加機能ではなく、プロジェクト全体の基盤です。
・利用目的の指定:「研究目的のみ」など、データの利用目的や商業利用の可否をユーザー側で細かく設定可能。
・匿名参加モデル:実名・電話番号・支払い情報は不要。ウォレットアドレスのみで参加可能。
・データの分離管理:識別情報はハッシュ化され、音声・環境データとは別々に管理。個人を特定しにくい設計。
・明示的な同意:録音はユーザーが同意した場合のみ実行。同意の有無やタイミングはブロックチェーン上で管理。

流れは大きく分けると、次の3ステップです。
1. アカウントを作成する
2. 録音タスクで音声を提供する
3. 貢献状況の確認
以下では、具体的な参加方法を順に見ていきます。
①アカウントの登録
Silencio Voice AI公式サイトにアクセス。
②プロフィールの設定
ネイティブ、または問題なく話せる言語を追加します(日本語を選択)。
①画面上部メニューから「Opportunity > Speak in Japanese」を選択し、「Continue」をクリックします。
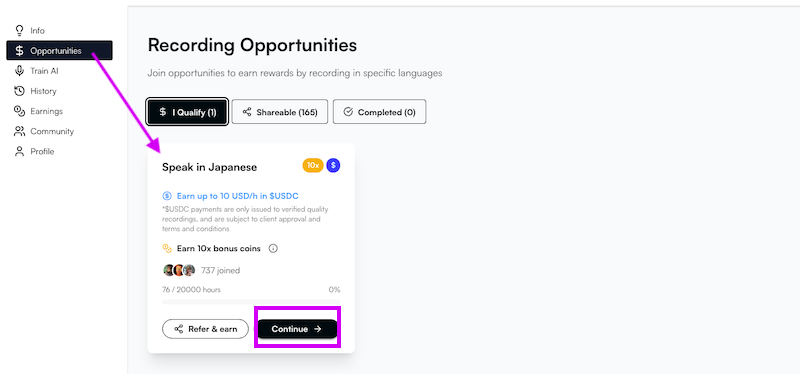
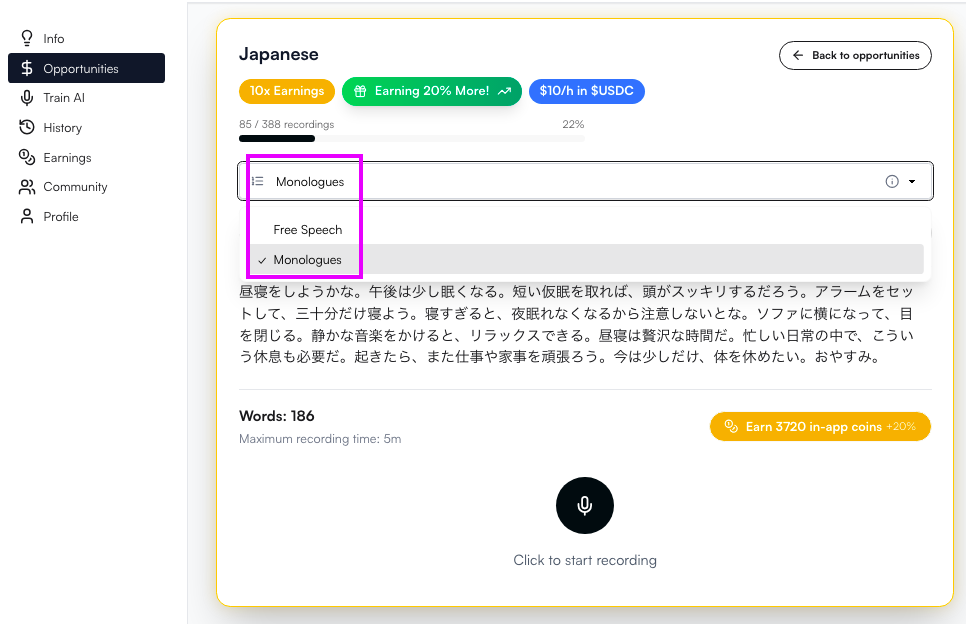
②「Free Speech」または「Monologue」を選択して、音声を提供します。
・Monologue(モノローグ):用意されたテキストを読み上げる
・Free Speech(フリースピーチ):与えられたテーマについて、自由に話す
以下に該当する場合、承認されない(Rejected)可能性があります。
・音声合成や機械的に生成された音声
・周囲の雑音が過度に入り込んでいる録音
・無音状態が長く続くデータ
品質チェックはやや慎重に行われますが、できるだけ静かな環境で録音すれば、多くの場合は問題なく通過します。
また、録音にはマイクを使用しましょう。
貢献状況は「Earning」から確認します。
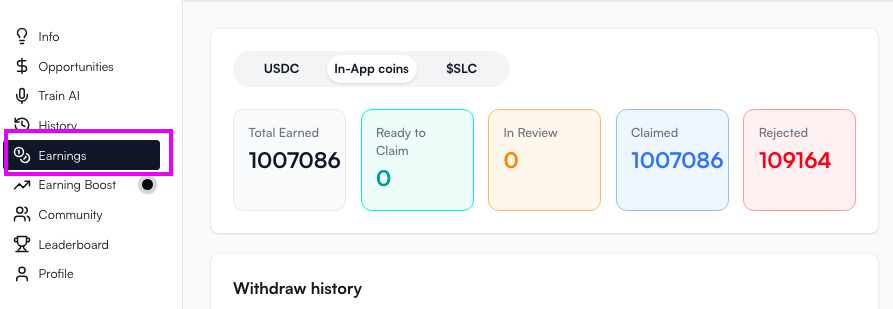
Silencioでは、音声データの貢献に応じてトークンやUSDCなどのインセンティブが用意されています。
これはプロジェクトのトークン設計の一部として組み込まれているものです。
Silencioのような分散型プロジェクトに参加する場合、いくつか押さえておきたいポイントがあります。
Silencioは、音声データ提供という新しいDePINの形を示すプロジェクトの一例です。仕組みを理解したうえで、自分のペースで参加を検討することが大切です。

今後は、広告やマーケットプレイスなどと組み合わさったSilencioのより大きな構想やDePINとしての可能性についても、別の記事であらためて整理する予定です。
参照:https://whitepaper.silencio.network/





